── R CMD build ─────────────────────────────────────────────────────────────────
* checking for file ‘/private/var/folders/36/1t9xtfl51px173qfsbg8tlcc0000gn/T/RtmpQWrj7e/remotes91b72c122d24/Genentech-phase1b-617e6f9/DESCRIPTION’ ... OK
* preparing ‘phase1b’:
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
* building ‘phase1b_1.0.0.tar.gz’
Warning in utils::tar(filepath, pkgname, compression = compression, compression_level = 9L, :
storing paths of more than 100 bytes is not portable:
‘phase1b/tests/testthat/_snaps/plotBetaDiff/plot-of-distibution-of-difference-of-two-arms-with-beta-mixture.svg’
Warning in utils::tar(filepath, pkgname, compression = compression, compression_level = 9L, :
storing paths of more than 100 bytes is not portable:
‘phase1b/tests/testthat/_snaps/plotOc/plot-of-simulation-result-for-single-arm-posterior-predictive-probability.svg’
Warning in utils::tar(filepath, pkgname, compression = compression, compression_level = 9L, :
storing paths of more than 100 bytes is not portable:
‘phase1b/tests/testthat/_snaps/plotOc/plot-of-simulation-result-for-single-arm-posterior-probability.svg’
Warning in utils::tar(filepath, pkgname, compression = compression, compression_level = 9L, :
storing paths of more than 100 bytes is not portable:
‘phase1b/tests/testthat/_snaps/plotOc/plot-of-simulation-result-with-relativedelta-for-posterior-predictive-probability.svg’
Warning in utils::tar(filepath, pkgname, compression = compression, compression_level = 9L, :
storing paths of more than 100 bytes is not portable:
‘phase1b/tests/testthat/_snaps/plotOc/plot-of-simulation-result-without-relativedelta-for-posterior-predictive-probability.svg’Practical Bayesian Statistics

Audrey Yeo
Thursday, March 27
08:00
DAGStat 2025
Berlin, Germany
Intro myself



Intro myself

Everything is a distribution
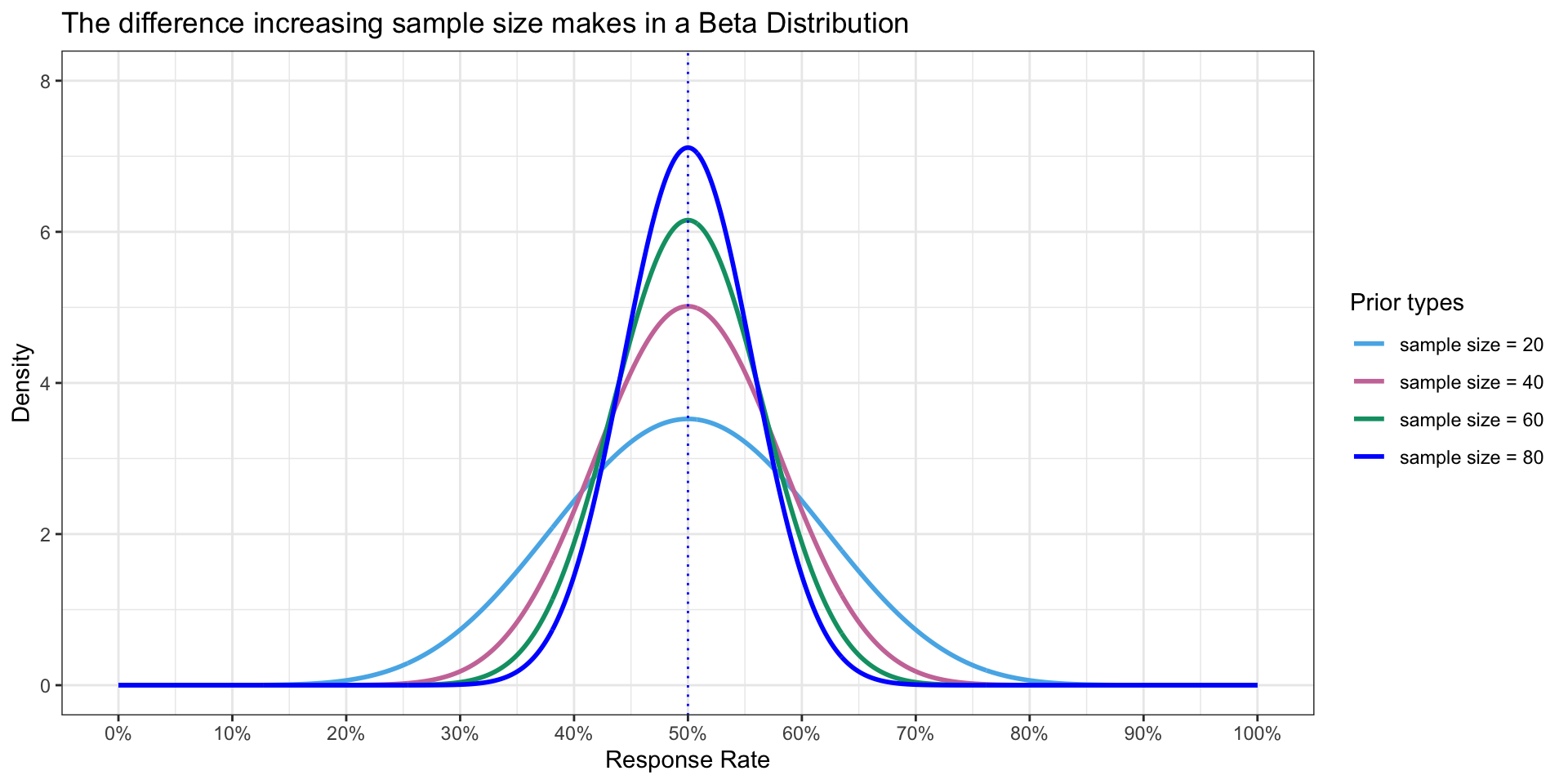
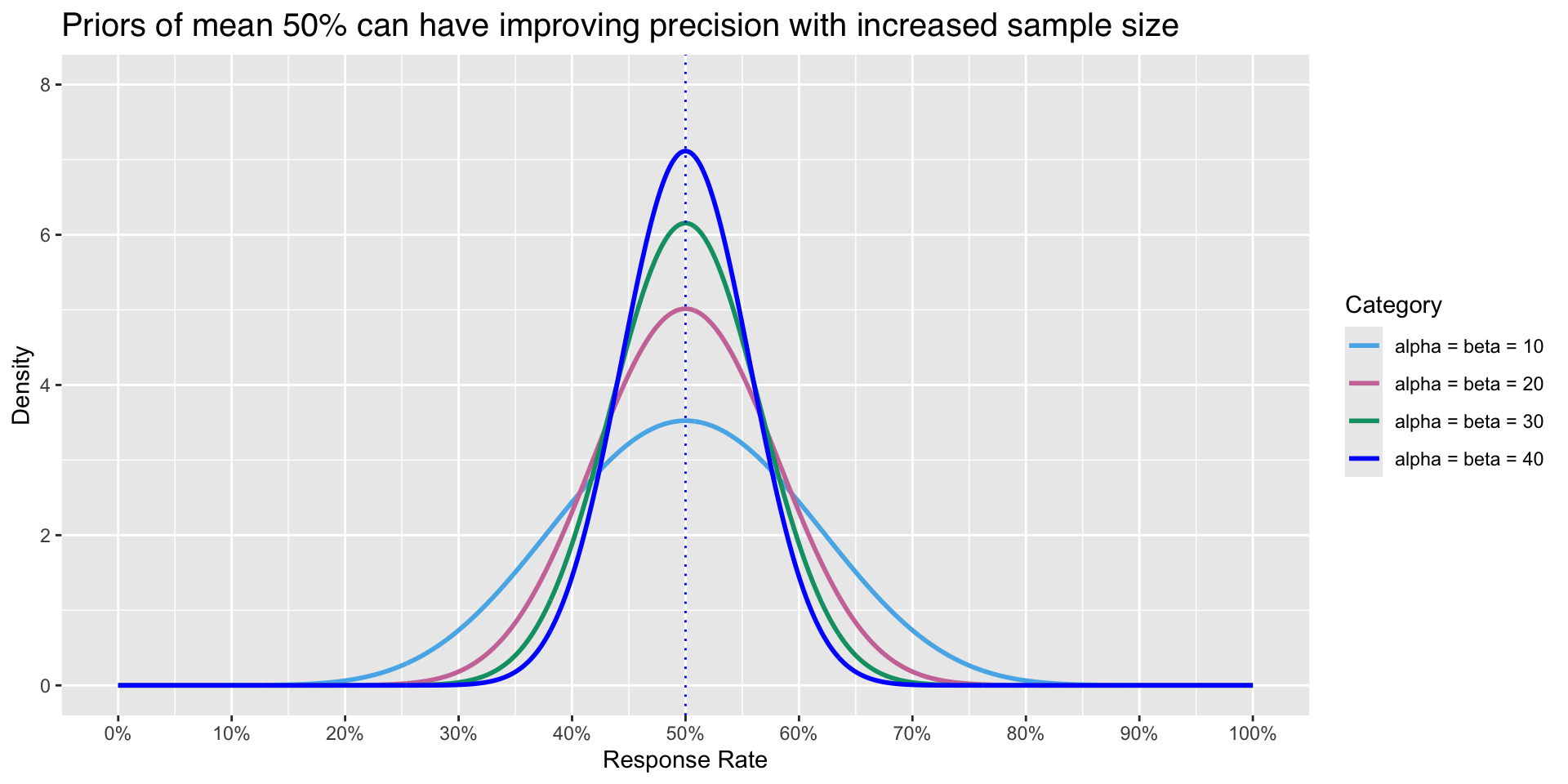
Upon visual inspection, increase sample sizes leads to
- Better precision
- Estimates and Credible Interval are more precise
These are benefits of the Bayesian paradigm
Using priors to improve precision
- Priors that incorporate higher \(\alpha\) and \(\beta\) parameters influence the posterior, given data stays the same (16 / 23 responders in likelihood)
Biostatistics solution I
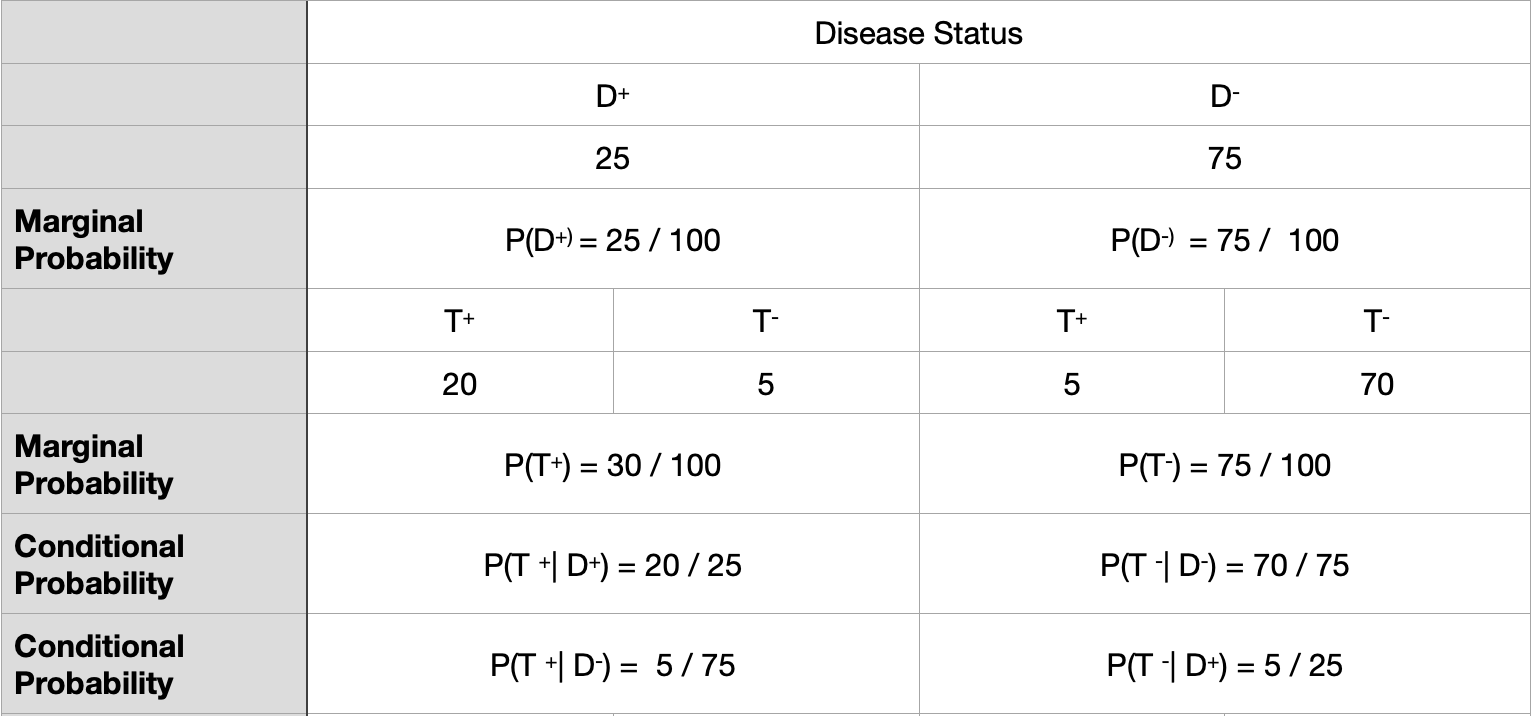
Biostatistics solution II
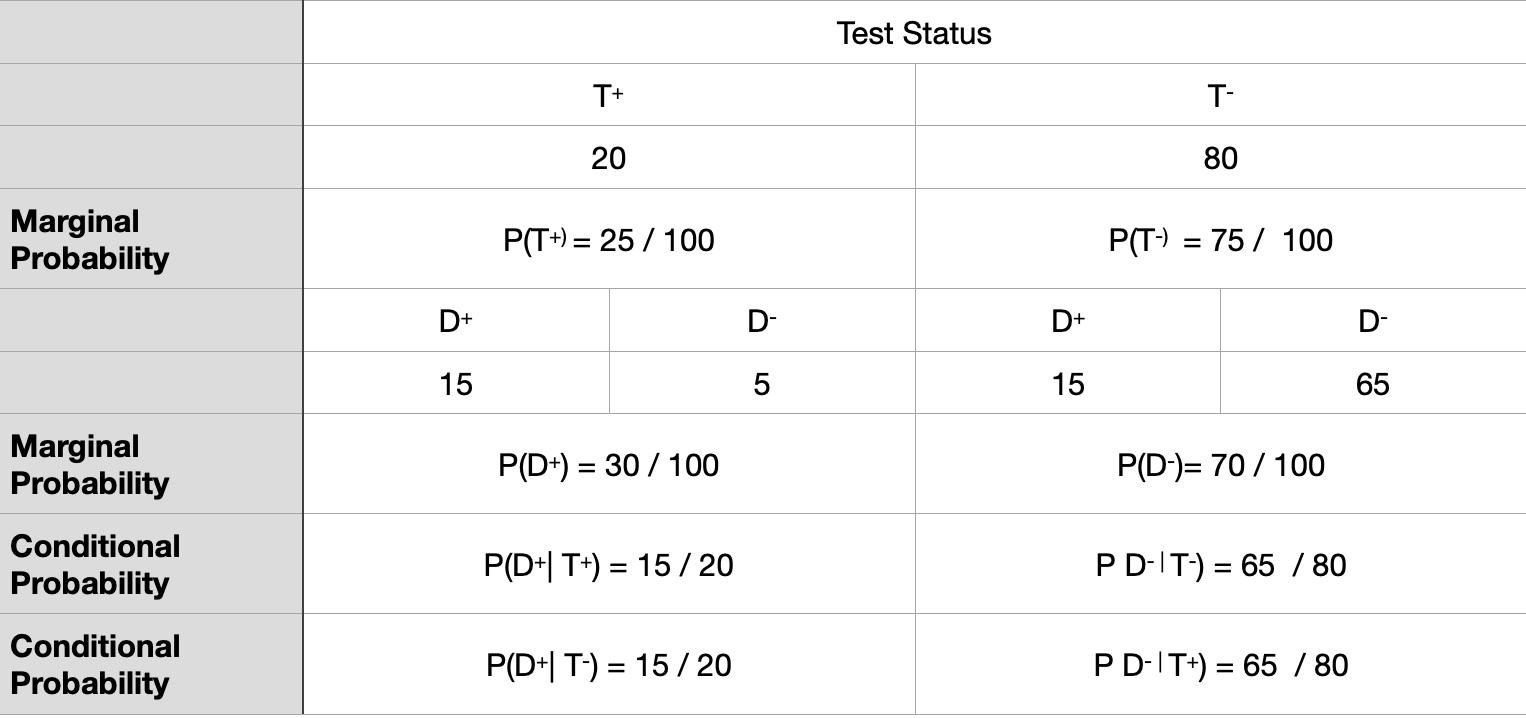
The Conjugate Prior
Merriam-Webster Dictionary on “conjugate” : coupled, connected, or related.
\[ {P( B | A)} = { {P(A|B)P(B)} \over {P(A) } } \]
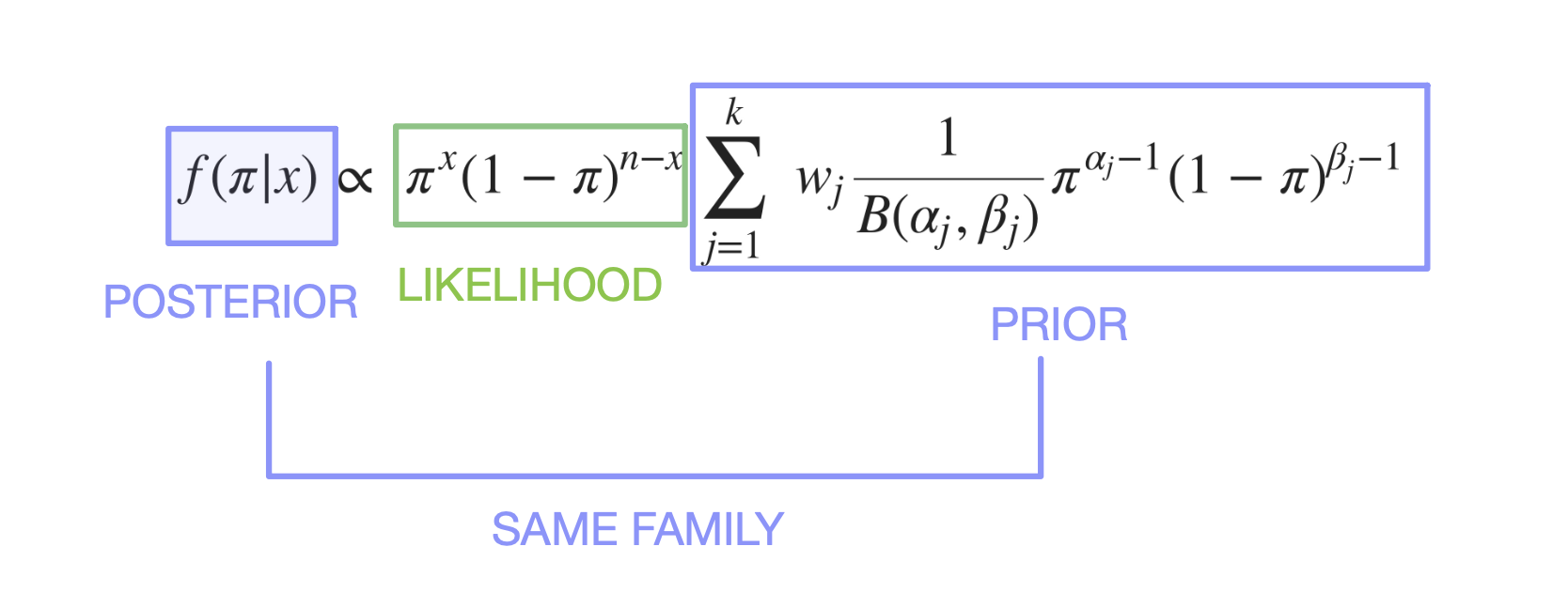
Choices
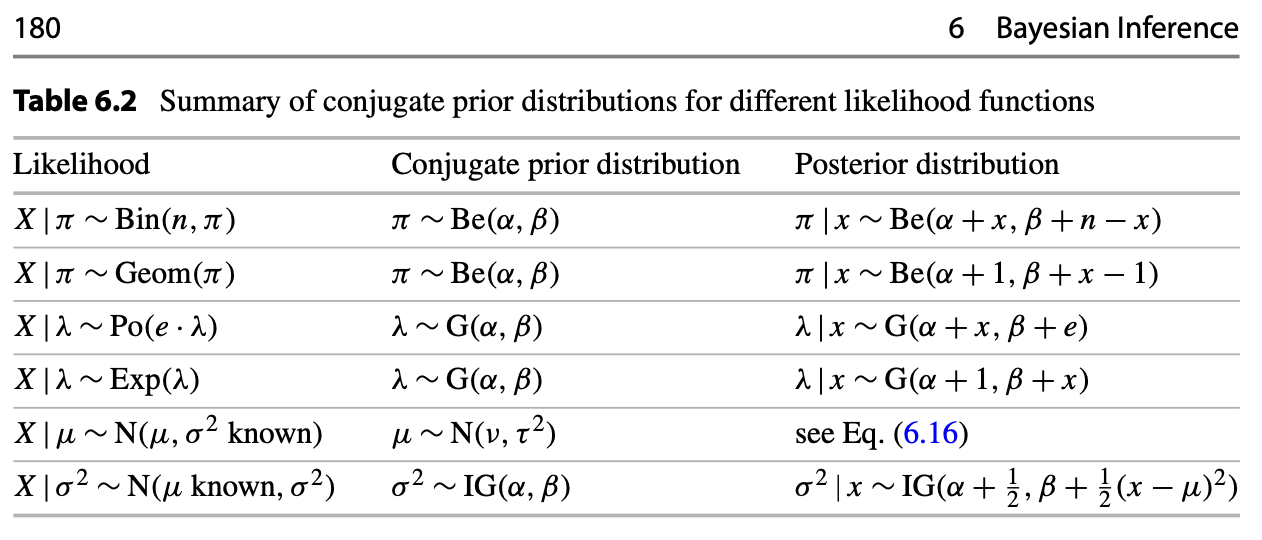
Summary table from Likelihood and Bayesian Inference from Held & Sabanés Bové (2020)
About phase1b
2015 : Started as a need in Roche’s early development group, package development led by Daniel Sabanés Bové in 2015.
2023 : Refactoring, Renaming, adding Unit and Integration tests as current State-of-Art Software Engineering practice.
100% written in R and Open Source.
website : genentech.github.io/phase1b/
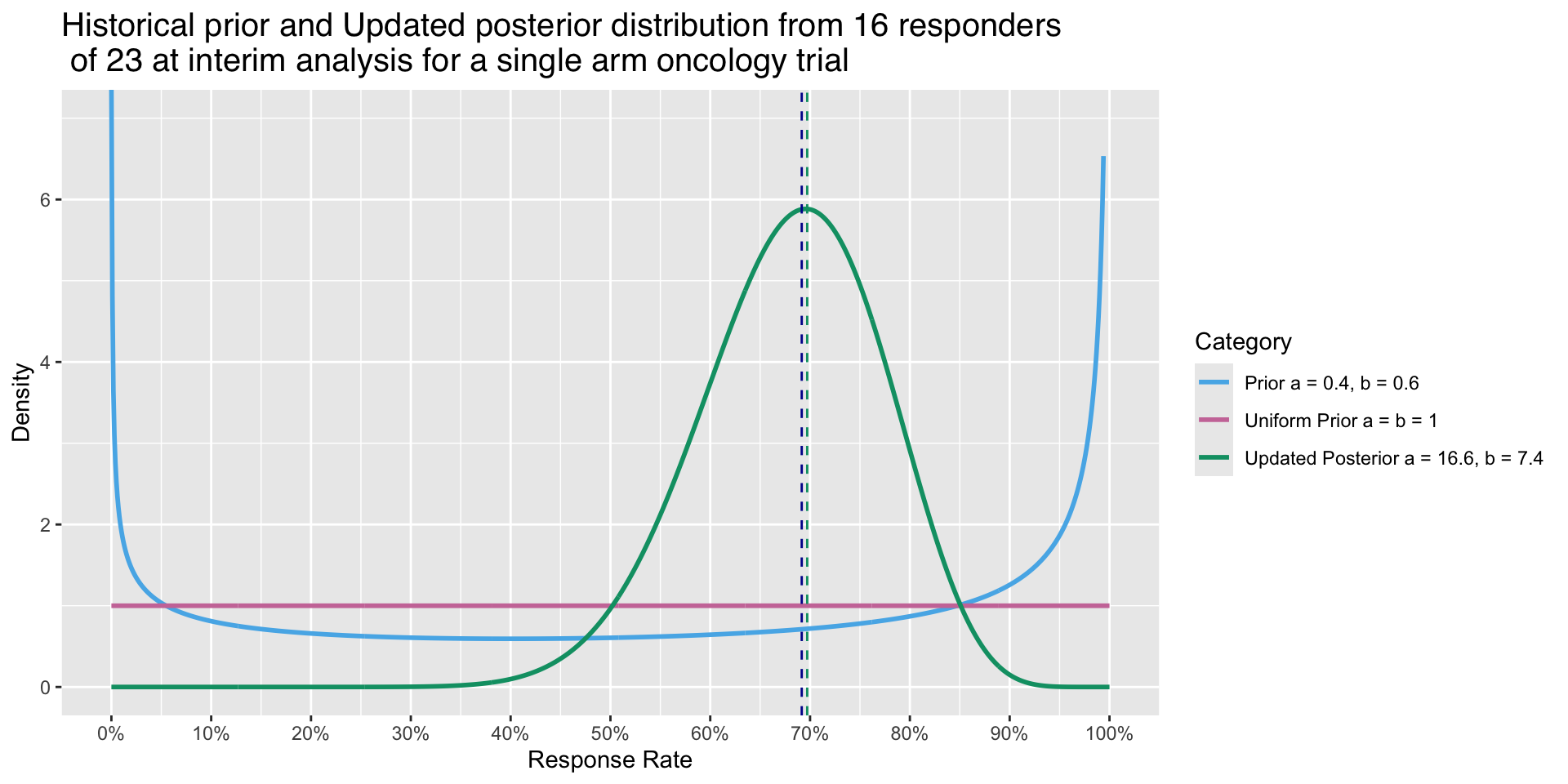
Graphical representation of the updated Posterior
- Prior parameters are \(\alpha\) = 0.6, \(\beta\) = 0.4
- Updated Posterior parameters are \(\alpha\) = 16.6 and \(\beta\) = 7.4
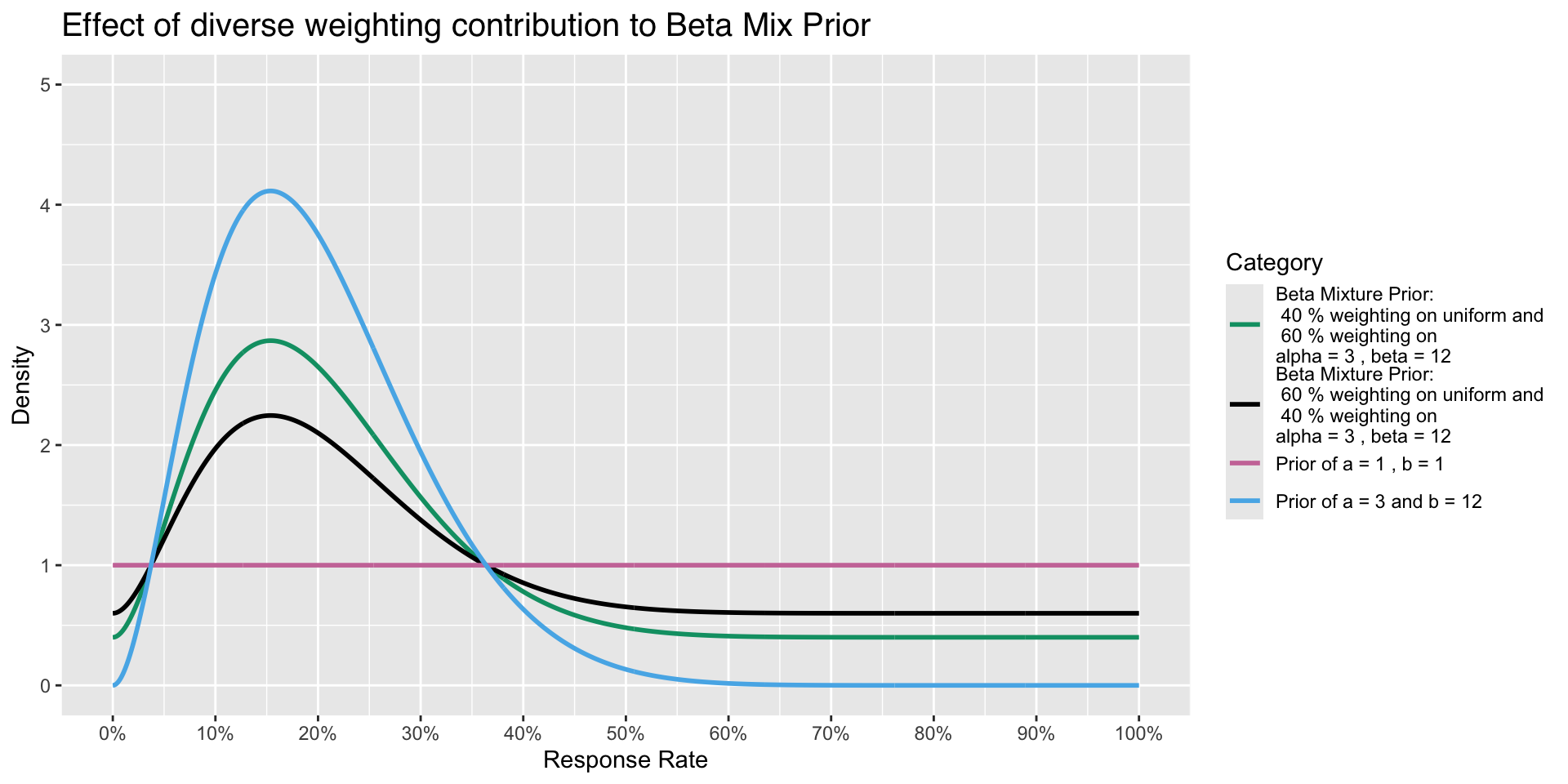
Effect on varying weight on different priors Example
A variety of Priors
- To illustrate how density of Prior changes with increased sample size even though mean is the same
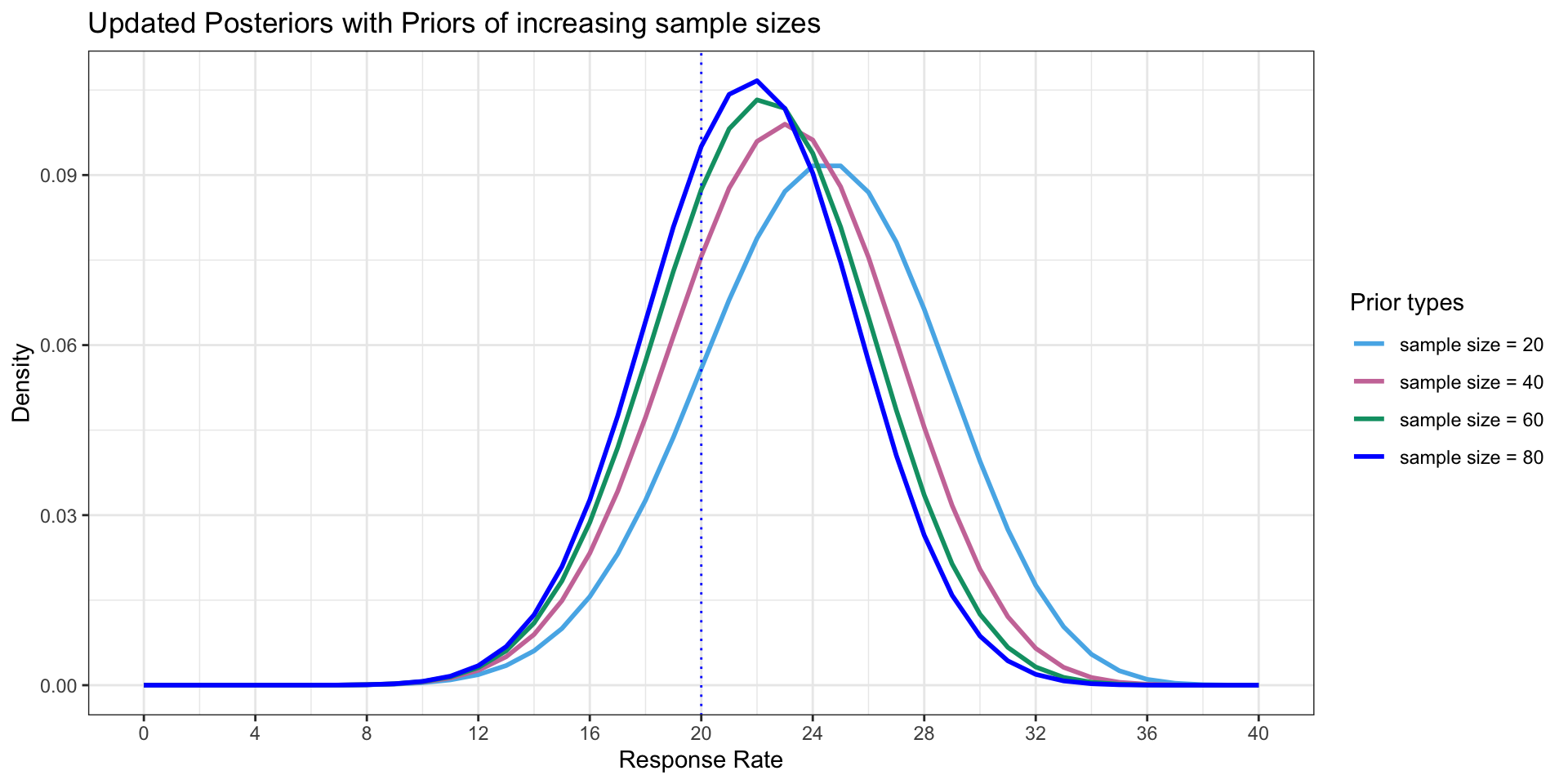
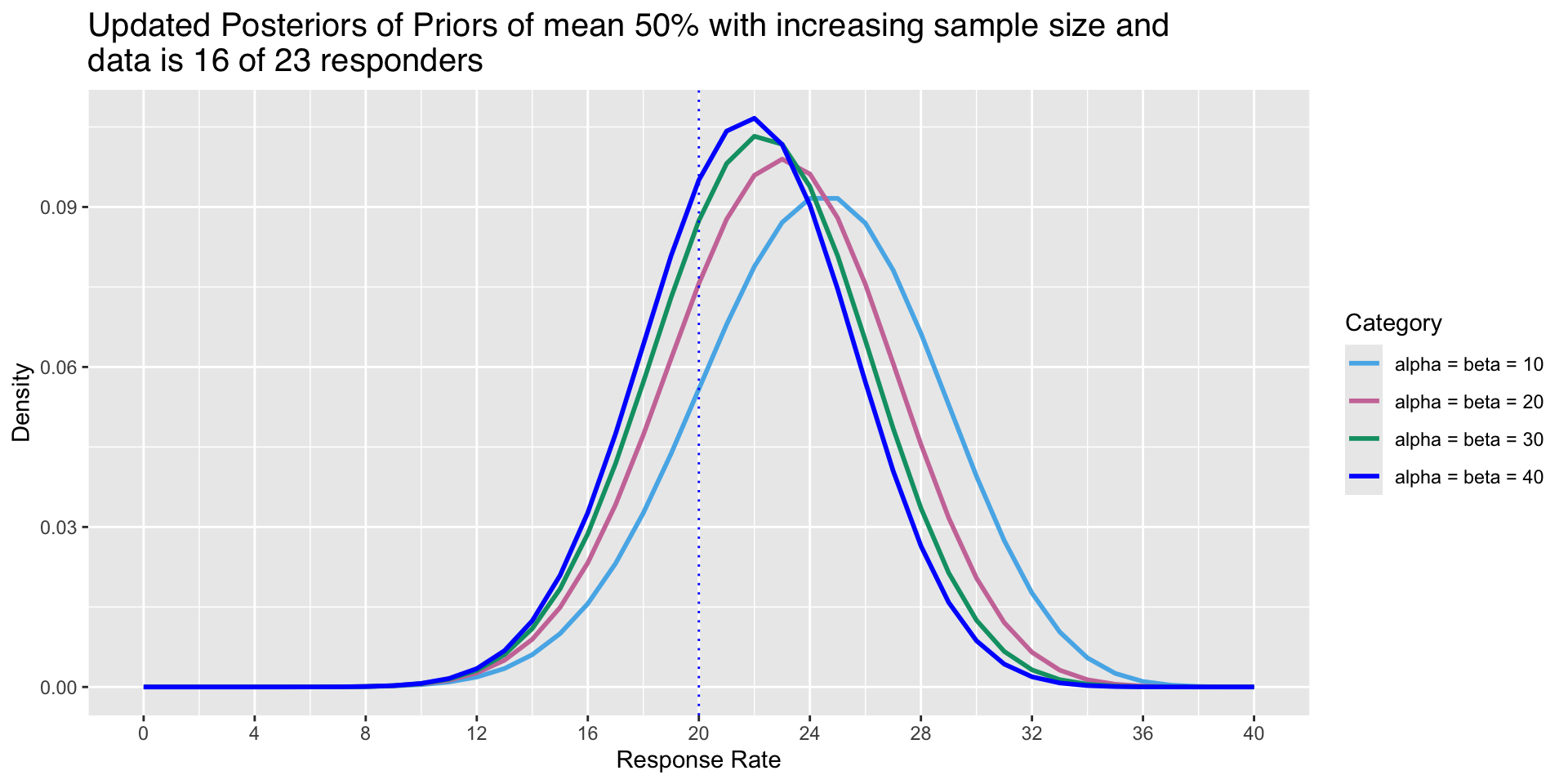
A variety of Posteriors
- To illustrate how density of Posterior changes with increased sample size even though mean is the same
Posterior Probability
- Interim trial is efficacious if posterior probability exceeds 70% or P( RR ≥ 60 % | data ) > 70%
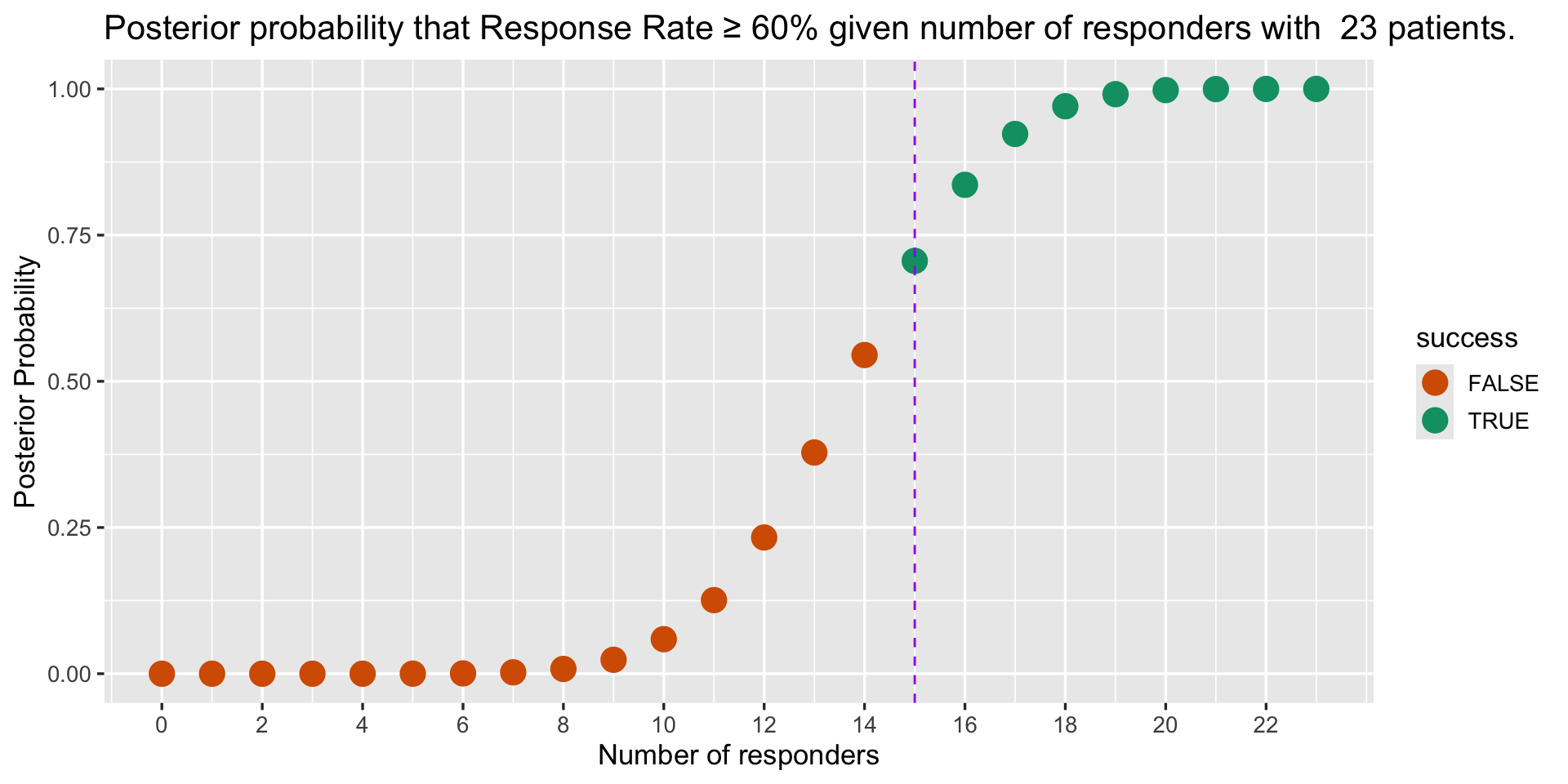
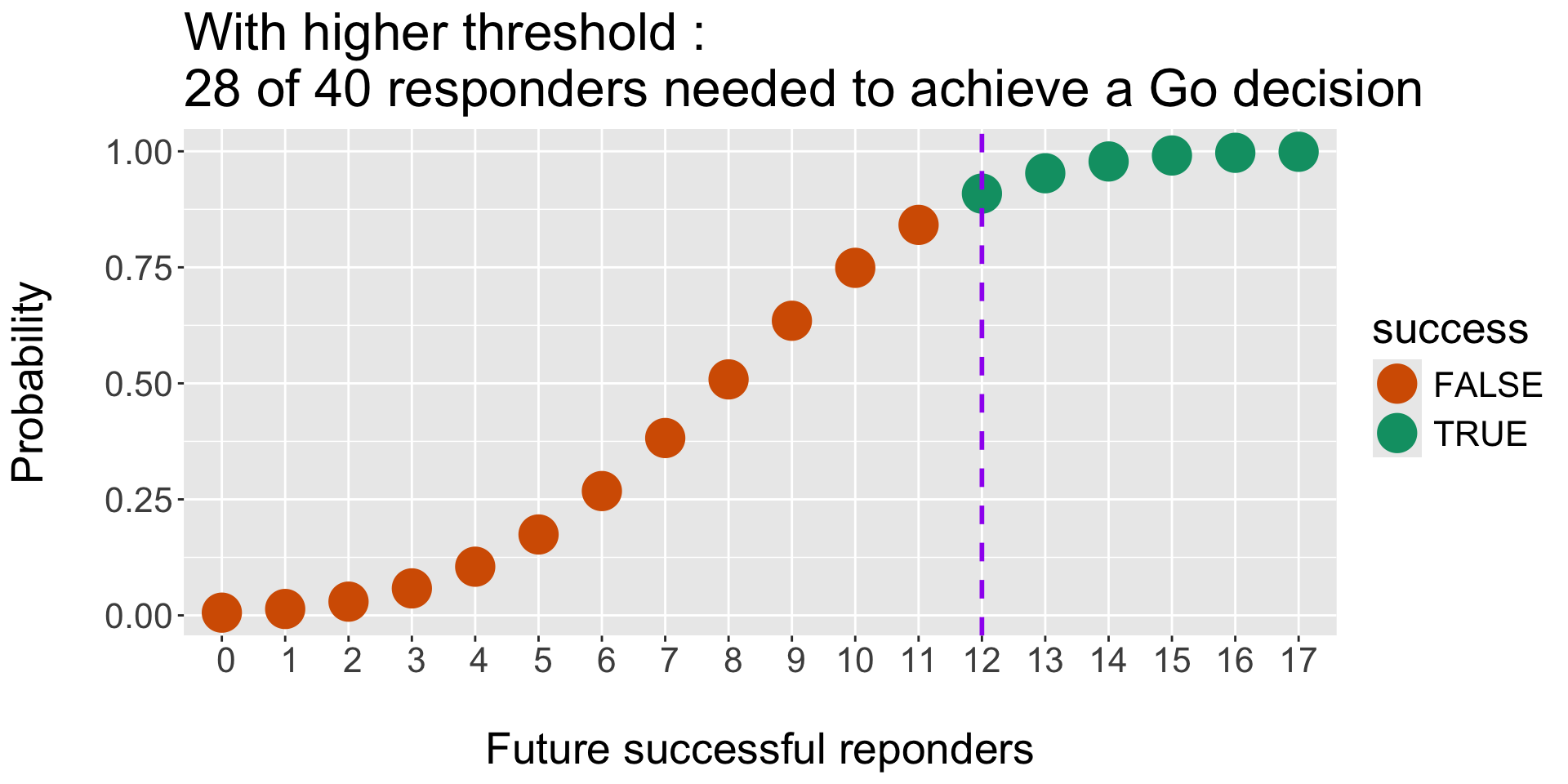
Predictive Posterior Probability
Predictive Posterior Probability is the Posterior probability of additional responders.
(Note : 40 - 23 = 17 remaining patients. Potentially 16 + 17 responders at final = 33)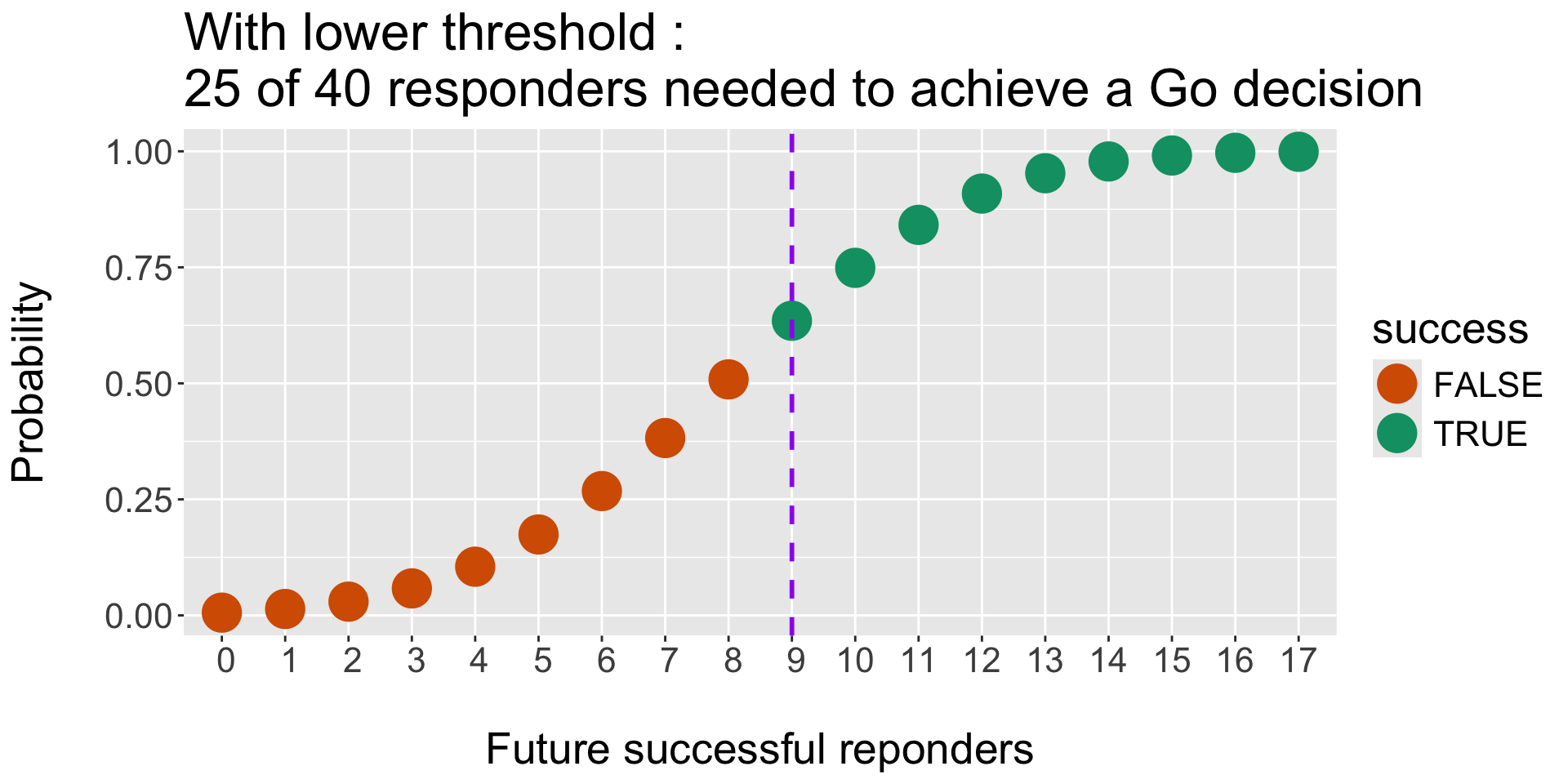
Operating Characteristics : Monte Carlo Simulations and threshold for Success (and Failure)
- Efficacy criteria, e.g. we would stop for Efficacy (Success) if :
Pr( RR > p1) > tU - Futility criteria, eg. we would stop for Futility (Failure) if :
Pr( RR < p0) > tL